

Contents
- About Scrapebox Tool
- What Are Proxies?
- Adding the Proxies
- Basic Proxies Settings:
- 2. Building The Footprints:
- How To Test Your Footprints For Better Results?
- 3. Scrapping
- The Harvester
- 4. Keywords
- The Keyword Scraper:
- The Google Competition Finder:
- 5. Links Building & More
- 6.Blog Comment Blasting
- Spinning Character:
- Fake Email Address:
- Spinning Comments
- 7.The Email Scraping
- 8.The Automator
- 9.The Scrapebox Add-Ons (FREE)
- Final Thoughts:
Hey, are you looking for the easy and effective guide to Scrapebox? If yes, then buddy you are at right place. As here at BloggDesk we are going to feature the most awaited guide- The Definitive Guide To Scrapebox in 2020.
Actually, we have used this tool earlier and wanted to share our honest review about this Scrapebox tool. So, sit back and get ready to start with in-depth Scrapebox Review With the Tutorial as well.

Scrapebox is one of the best and reliable SEO tool in the market. You only have to pay once and use it to quickly rank your sites in all the search engines like Google, Bing and Yahoo. It generally automates most manual reference activities. It has many many advanced useful features that can help you in ranking higher in the SERPs.
Today, in this post we’ll launch the Complete Scrapebox Guide that includes easy tutorial along with the detailed use of its features and add-ons as well. Actually, this post has been broken down into sections so that you can relate with the guide easily without being overloaded with all the information at the same time. So let’s get started here.
About Scrapebox Tool
Scrapebox is often referred to as “Swiss Army Knife for SEO” and to be honest, it probably is without having any second thought. What this tool can do is amazing and outstanding, an old tool that is mainly updated regularly, but it has a very simple user interface that still makes it one of the best SEO tool in 2019.
Scrapebox is a tool that has existed for many years, and I would be surprised if there was an SEO Evangelist who does not try this tool. However, for the average user, it can be a fairly complex tool that is difficult to navigate, and you probably will not know how to extract the data you’re actually looking for. But don’t worry we are here to help you out with this Scrapebox Tool.
You can easily get the Scrapebox tool from here, it mainly costs $ 97. Often, people mainly complain about the price of this tool, but for what this tool does, it really deserves to pay $ 97, which gives it a license for lifetime and that quite impressive. If you want a tool to provide data that is worth using, it is always a cost, because developers need to continue working on the tool to make it work for you.

If you so have experience with Scrapebox tool then please do not hesitate to go directly to the other sections, but for beginners, we will review everything. But first you have downloaded and installed your copy of Scrapebox (this can be done locally or through VPS). It really important now that you buy a series of private proxies if you are considering serious difficulties.
Now most, probably you might have the question, what are proxies and why actually we need them in order to use this Scrapebox tool. Let’s find it out together.
What Are Proxies?
A proxy server is an intermediary between your PC or MAC and a specific destination on the server you wish to visit. Normally, a normal connection uses its IP address and connects to the desired server.
When you browse the site and you can not access with your IP address, the proxy servers help you access the site by redirecting your IP address using multiple connections and leaving it on the Internet to your desired pages.
And here the proxy server generally acts as an intermediary for Scrapebox to retrieve data. Our main goal, Google, does not like that your engine is hit several times from the same IP address in a very short time. That’s why we use proxy servers. Then, the requests are distributed to all the proxies so that we can recover the data we are actually looking for.
We have got a set of cheap and reliable ScrapeBox private proxies. I recommend you get at least 20 private proxies to get start. You can always add more later if you need more, but it’s a good ideas to simply start with 20 proxies. Proxies are paid monthly. The company you have used should send you a new list every month by email and you should pay them accordingly. Make sure you use the reliable and affordable private proxies so that you can’t get stuck in future.
-
Adding the Proxies
Now that you have your private proxies, it’s the time to simply add them right to Scrapebox. Your proxies can be stored directly in Scrapebox through a simple copy and paste function. And I recommend you to do that so that you don’t get confused.
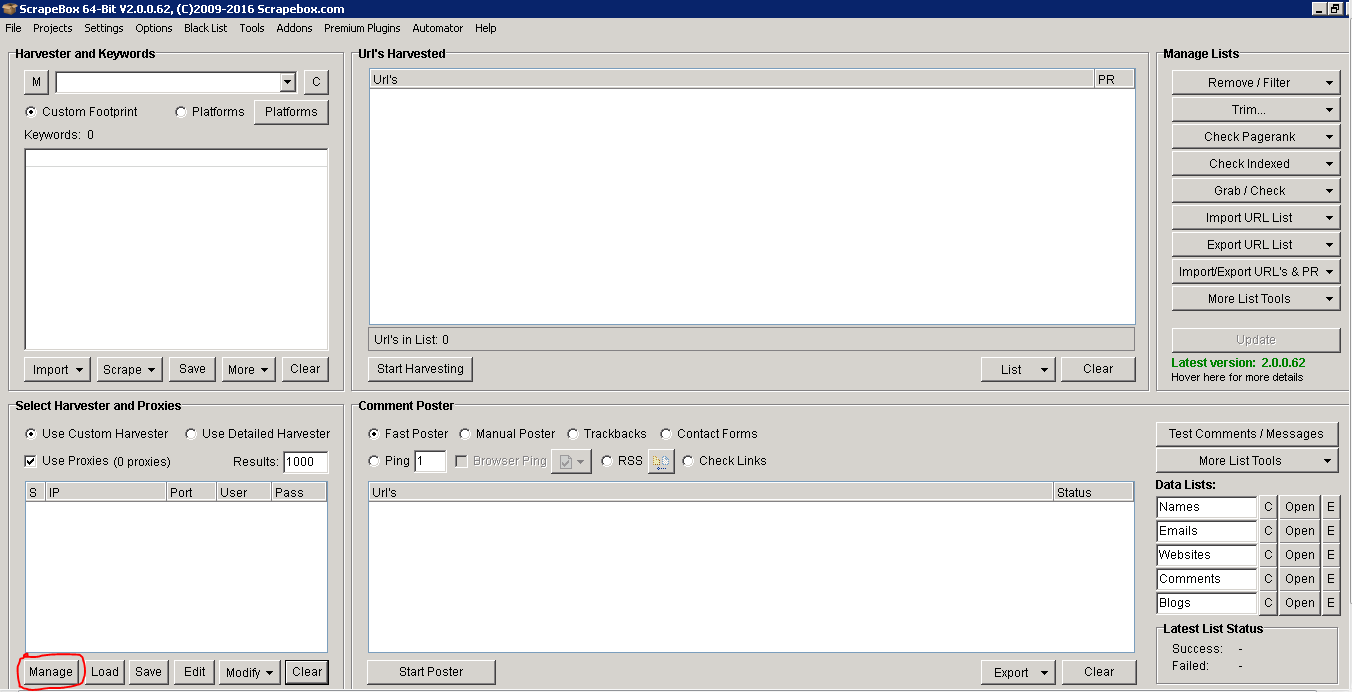
Screenshot Credit: https://www.craigcampbellseo.co.uk
To save your proxies, just click on the “Manage” button in the lower left corner of Scrapebox. This will open a window where you can insert your proxies easily and effortlessly. There is also an option to collect proxies. Here is a series of public proxies you can use, but I would not recommend that. Recently, Google has abused most public proxy servers and included them in the blacklist so it’s not a better idea to use them directly.
When you buy your proxies, you probably get them in a format just like: IP Address: Port: Username: Password. If this is the format you have received, continue and paste your proxies right into the Scrapebox. Otherwise, you must organize them in this format for Scrapebox to accept them. Make sure you organize them in the format that I have listed earlier and then just paste it right to the Scrapebox tool.
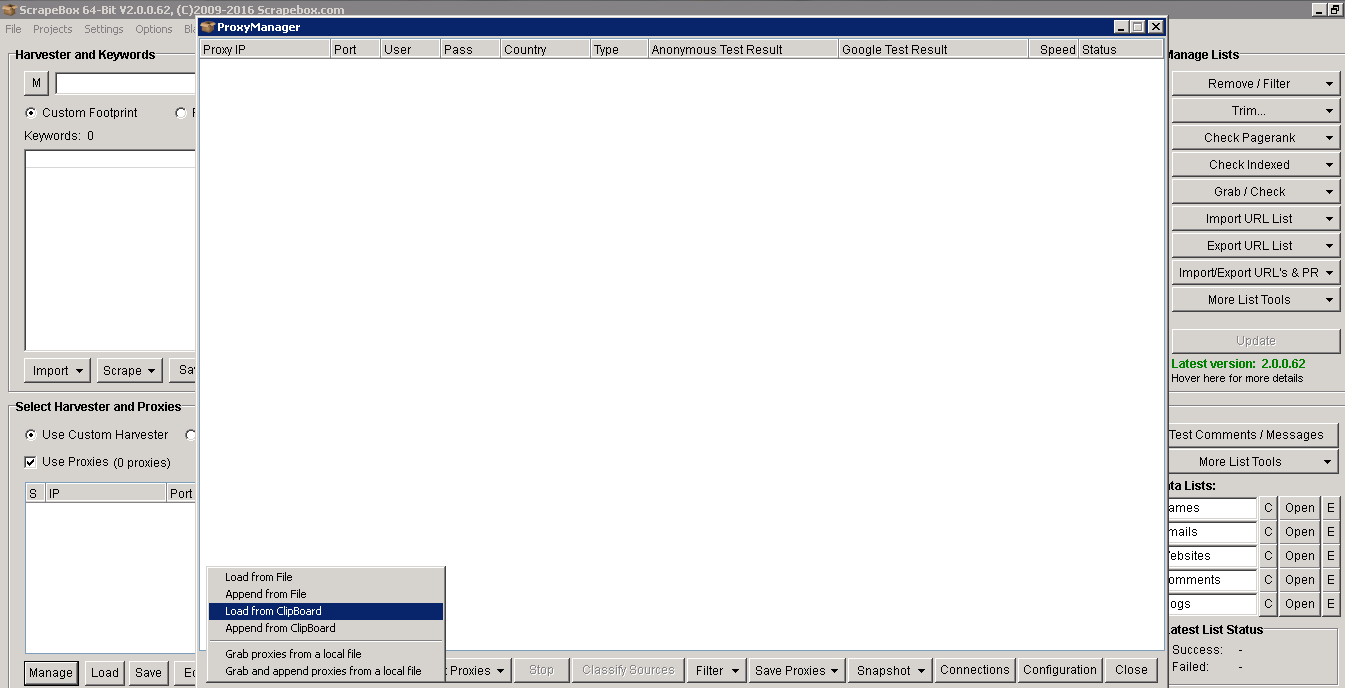
In order to add them, simply copy the proxy servers from the recipient’s email and just click on the Upload from Clipboard option. Now all your proxies will be in front of you, and you must test them quickly (if one or two errors occur, try the failed proxies again and you must follow them). All proxies sent will be highlighted in green and all failed proxies will be highlighted in red. Just make sure you check them properly.
One last thing is to filter all those who do not work with Google. Everything that does not work is completely useless and will obstruct you in the process. Make sure you filter all the proxies in order to check them if they are working or not.
Once you’re done simply save your proxies right with Scrapebox.
Basic Proxies Settings:
Once you have defined your proxies, you can select some settings. In most cases, all settings can be set by default but here you have do it in a correct way. If you have many proxy servers, you can just set the number of proxy connections that are connected to Google. All you need to do is to go to the tab ‘Connections, waiting time and other parameters’. If you generally use 50 proxy servers then you should probably use between 5 and 10 connections.
Once the proxies are set up, you must understand the fingerprints before you start scratching. The next topic covers your scrapebox tracks.
Now we’re moving to another section of this guide.
2. Building The Footprints:
But before building the footprints we must have some idea about footprint too. So let’s find out what Footprints actually is in Scrapebox.
What Is Footprints?
Footprints generally appear regularly on web pages. For example, the words “blogging” or “WordPress”. The first can be seen on many websites with WordPress, as it appears in the standard design, and the second on many blogs powered by WordPress. That really gives the impression.
If were actually planning to find a blog on a WordPress site, then you can enter that footprint with some specific keywords. Scrapebox finds many websites for you without any delay.
What you want to do is create your own good footprint. When using Scrapebox, it is important to have good footprints to get the best results in future. Building yourself requires some time and research, but if you have some good ones, you can use them again and again for many times.
When searching right for footprints, you can just use some of the following commonly used operators: inurl:, intitle :, intext:.
Even you can download some common footprints from the web simply by making a search.
How To Test Your Footprints For Better Results?
The best way to test your footprint is to simply google it. Now you can judge the number of results displayed for your particular search. If you only get between 1,000 and 2,000 results, your fingerprint will be unusable. You should try to find a product that works well before it is used for you. Make a list of all the footprints and just , separate them into various blog platforms, etc. It’s a good idea to start scratching. Once you are satisfied, you can put them to the test.
Now you have a good set of footprints and now it’s the time to start scraping.
3. Scrapping
If you really want to scrape big then you should keep Scrapebox running for a long time like few hours or a day. Right for this purpose, some may opt for a virtual private server (VPS). That way, you can set and forget Scrapebox, just close the VPS and run your business on your desktop without any recourse. Also keep in mind that Scrapebox is only a PC, but you can do it with Parallels. If you are running Scrapebox in Parallels, you must increase the RAM allocation for your PC. Meet me if you need help installing a VPS.
Here The Number Of Things Your Need To Consider For The Major Scrapes:
- Number of the proxies
- Number of connections
- Number of Request
- Time between each query
- Effectiveness and Speed of the proxies
The default setting should be useful, depending on the number of keywords you specify, the generally determine the duration of the note. It also depends on whether you use public or private servers and their number also, you can even change the number of connections you use.
And here the next part is to add the Keywords.
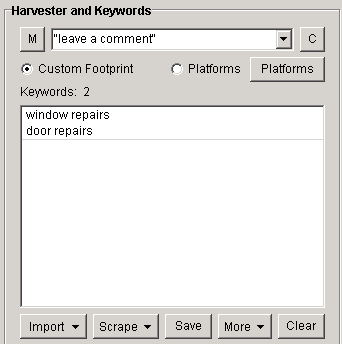
You can include all of your keywords that are used next to your footprints. So, if your footprint is simply “blogging” and has some keywords like “WordPress” and “Blogging,” your searches will look like this:
“Blogging” Powered By “WordPress”
In the next step, simply select the Use proxy check box. Otherwise it will not be executed properly.
This section also shows “Results.” It’s a pretty simple game. This is the number of results that you get from each search engine. If you select only some sites, you can select 50 results for each of your keywords. However, if you delete and lots of sites, then use a maximum of 1,000 per keyword and that’s better.
The only problem here is that good footprints can generate more than 100,000 results. In order to refine your results better, simply use empty words. Like for example, use the proxies to simply leave comment and repair window of 30,000 results.
You can try many more filter words in order to get more accurate results for finding the the best footprints possible and also the data scraping t
Now that you have your footprints, your keywords and your empty words, it’s time to start your scrape. If you are simply using a scraper right with a large number of keywords then you should run it on your VPS so that everything works fine without any hindrance.
When you return, it should be complete and simply show the entire list of the URLs that has been scraped . If your list has not been completely searched, you can leave it longer or stop manually it according to your needs and requirements.
And if you cancel, you will see a list of keywords that have been completed and which one not completed. All results that come back with nothing have not yet been investigated or results have not been found.
Right when you finish your search, you can export all the incomplete keywords to retrieve them where you left them.
The Scrapebox can only have one million results at one in harvesting. And here it will automatically create a folder with the date and time that contains the 1,000,000 and continue in the next scrape. It’s great, but there will be many duplicate URLs make sure you find and and avoid it using.
This is easy to eliminate when many URLs are below the collector’s limit. You can do this by opening the Delete / Filter section and removing duplicate domains and URLs that are duplicate. However, if you work with several files, you need Dupremove– Actually it’s a new Scrapebox addon that generally combines millions of URL and remove duplicate URLs and domains in all files very smoothly.
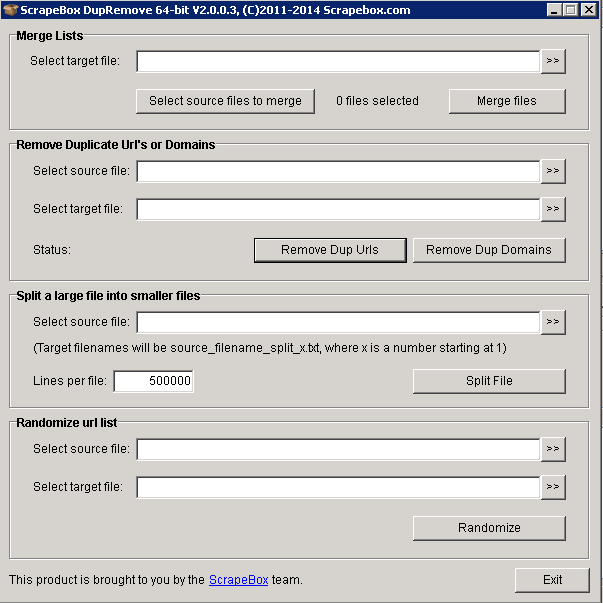
The Harvester
If you really want to scan a site individually, you can enter the URL (including http: //) in the custom Footprint area in order to see a complete list of all the pages. From there, you can use the email retriever that I will show later in the review or check the backlinks on the site.
There are many things that you can easily do with your list of captured URLs. On the right side many functions are shown.
Delete / Filter: this section allows you to clean any unnecessary URL and sort your list in the order of your choice. In this section, you will delete your duplicate domains and URLs. You can even delete URLs that contain certain words, numbers of a certain length and even delete subdomains.
Trim: you can delete all the URLs of the root domain by deleting the subpages of the site from your compiled list.
Check Metrics: check the URL and domain metrics in Yandex.
Check Indexing: after making a list of URLs, you must verify that the site is indexed in Google. You can also check if it is indexed in Yahoo or Bing.
Grab & Check: Right from you can retrieve many URLs. You can get everything from comments through images and emails.
Import URL list: You can import a list from a file or paste it into the reaper from a copied URL list from your PC. You can also add it to the existing URLs of the collector.
Export URL list: there are many file formats that you can export, including text, Excel and HTML.
Import / export URL and PR: allows you to import and export URLs with your page rank.
Other list tools: find functions such as random order.
Next I will explain the keywords in the Scrapebox.
4. Keywords
Here you can simply use this tool to do the best Keyword Research for any niche. And trust me with this feature you’re going to find the best working Keywords for your campaigns.
The Keyword Scraper:
With this tool you can enter some keywords. Search the selected search engines and find search terms similar to the ones you have actually entered. First, you must click the “Scrape” button, that is mainly located just below the keyword section. There a window will appear like this:
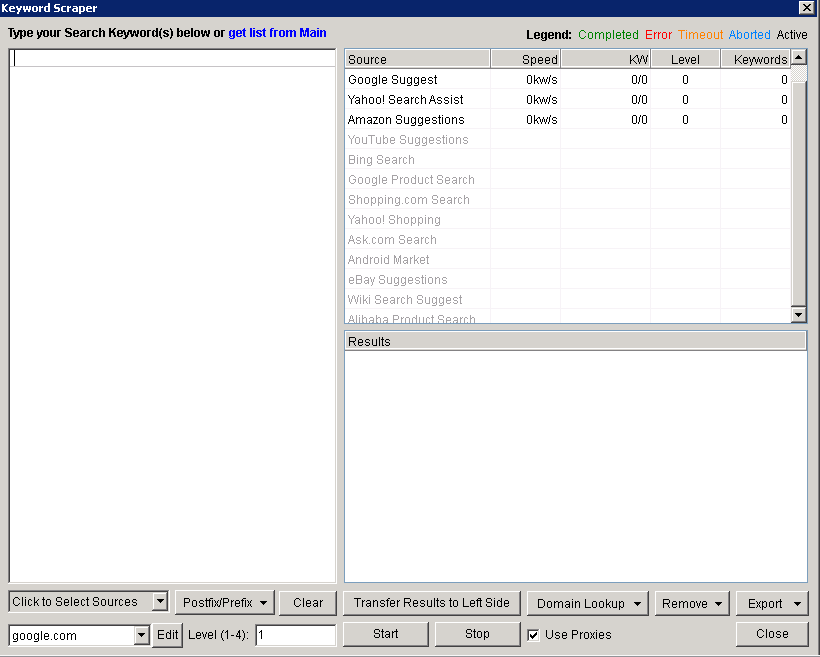
If you just click on the menu in the bottom left, you can select the search engines to which the scraper must refer and get the results for you.
Right after selecting your sources, you must enter some words that you want to scrape for. I entered the words “Blogging” and “WordPress”, clicked “Start” and the suggested list is displayed. Bravo we have got our results and that is great.
This is a list of best and unique keywords generated by Scrapebox. You must click on the “Export” button in order to save the keywords right in the Scrapebox and then restart the process with your new keywords and phrases. You can continue in this way until you get the ideal amount. Now you can install the Add-on called- Google Competition Finder.
The Google Competition Finder:
This is another add-on that is basically available for free in Scrapebox all you need to do is simply install it. It also allows you to simply verify the number of Google indexed pages right for each of your keywords. It is very useful to know the competitiveness of each of your keywords. In order to use the add-on tab and once you install it simply load the keywords right in the Scrapebox to it easily.
Right once you have finished with the keywords, just check the corresponding box. That truly indicates that your keywords mainly uses quotes in order to get more accurate results easily. You can also simply adjust the number of connections that is generally used. However, I recommend that you set “10”.
After exporting the file as an Excel file, you need to just click on the “Export” button. Simply open the Excel file and simply sort the files right from lowest to highest, in order to simply get a better overview of the competitiveness of each of your matching keywords. From here you can simply start organizing your keywords in ascending order if your word volume is very high. Just follow all the extensions carefully.
5. Links Building & More
Right with the Scrapebox you can simply find many ways to for the link building. For example, suppose you find a WordPress blog site for a keyword on pages 4 or 5 that you want to rank for. Here all you have to do is to create a profile, comment on some articles and then simply insert a link in the comments of your own website.
With Scrapebox, you can use some footprints that scan a large number of websites with specific platforms. To do this, collect some URLs using a list of keywords. Once the list has been compiled, delete all of the duplicate URLs and open the “Scrapebox Pages Scanner”.
Here the Scrapebox Page Scanner generally scans each of your websites and shows the platforms that they generally use.
If you click right on the “Edit” button below, you can simply edit the footprints currently used. As you can see, Scrapebox contains several standard footprints, which are simply a group of popular platform names. You can also add footprints created here. The footprints used here do not match those of the harvest.
The difference is that the scanner searches the source code of all locations for the footprints that is generally determine the platform used. Taking the time to make good footprints s will give you the best results if you find the platform of your choice.
Simply load all of the harvested keywords and just start the process. The analysis is done and the platforms are displayed in the results tab. And right once it is finished just click on the “Export”button to create a file that separates your websites on the respective platforms too.
If you are satisfied with the list, perform the checks described in the previous topics, for example: For example, your page authority (PA) and your domain authority (DA), and perform your own additional external search to help identify the best site links.
So in this way you can simply use this tool to for the purpose of the links building too.
6.Blog Comment Blasting
Blog Commenting with Scrapebox means that can leave same footprints if it is not done correctly. Comments like these should never done on your money site. If you make such comments, you must do so on their third level websites.
When harvesting a list of sites, you should review the PA (Page Authority) & DA (Domain Authority) of each site and the number of outgoing links from the site to in order to get the best results.
Searching for the websites right with weak outbound links and high Page Authority. Problems can arise if you do not take the time to make good comments and have enough false emails to leave a footprints easily.
If you have defined a URL correctly, you can create your profiles. You need this:
Spinning Character
Fake emails Address
Spinning comments
List of websites to place links.
Now we have got all the things that we actually need and let’s start the process:
Spinning Character:
Use the keyword scraper to capture an extensive list of all the sources and enter up to 100. You can also add generic anchors and save your file as a simple text file.
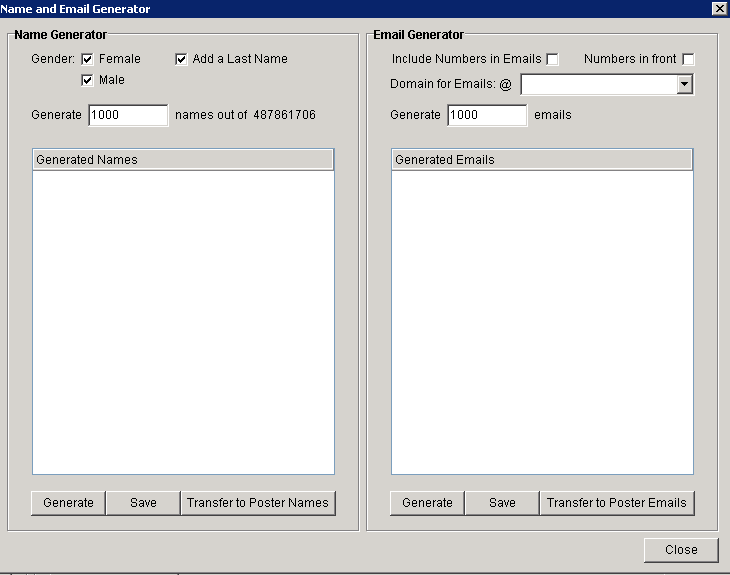
Fake Email Address:
The next step is to simply create a complete list of fake emails. Fortunately, Scrapebox has a great little tool for this purpose that you can use to generate the fake keywords. On the Tools tab, open the Name and Email Builder.
Spinning Comments
One of the easiest ways to get an extensive list of comments is to include comments from similar sites in your niche and have them run. The Scrapebox has a feature that allows you to get comments from the harvested URLs.
Simply Click on the “Grab / Check” button and then on “Extract comments” from the list of harvested URLs. This will tell you what platform each site uses and how many comments have been successfully deleted. When finished, save your list as a text file.
List Of The Website To Simply Place The Links:
Websites
Just create a list of sites that you want the backlinks for and name it as the websitescmt.txt.
Auto Approve List
Here you need to just make a search ‘instant approve website lists’ right Google you will be going get plenty of results, just grab one of these lists. Just use these sites and save these right on Google Spreadsheet with the Page Rank and the DA (Domain Authority).
You can then upload this file to the Scrapebox and it start dropping the individual comments on the list of your selected website.
7.The Email Scraping
Scrapebox os one of the best and reliable too right for extracting email addresses from the harvested URL lists. Start by capturing your footprints and then adding all the keywords and then just start the scraping.
Right once you have got your list, simply delete the duplicate URLs and now go to the “Grab/ Check” option and select “Enter emails from the harvested URL list”.
You can configure it to use only one email per domain, or you can retrieve all available data easily. But initially I recommend using all emails since a user can add a single email in the comments instead of a relevant email from the website).
Now just click on Start and a backup copy of each of the sites searching for email addresses. When finished, you can save everything in a text file easily. You can also filter emails right with specific words before saving the file. This allows you to refine the search for your wishes.
Verifying Your Emails:
The next step is to check if the emails are working or not. Mainly for this purpose I recommend you using a tool called ‘GSA Email Checker’. When you have finished all your emails, you can import the text to this tool and start testing it.
Also you can even run can run a quick test or a full test right for each email, except that the quick test connects to the server. It is a better idea to do a complete test in order to get more reliable results. Once the results are complete, you have the option to export only the emails that work correctly to a text file and you’re done.
You have scraped the authentic emails that you can use for email marketing or anything else on the basis of your needs and requirements.
8.The Automator
This Scrapebox tool is not only the most redundant SEO tool incorporated in almost every aspect, it can also automate most tasks. And really trust me this can really help you in automating most of your tasks.
And for $ 20, this premium Scrapebox tool can be yours. In the tab, just click on Available premium add-ons, buy the add-on right through Paypal and you can download it right to your Pc.
Here you have to let your imagination fly. With the Automator, you can easily group large task lists and efficiently automate your scrapbox processes hassle free. The beauty of the Automate is not only the efficiency, but it also has the ease of installation. And even if you’re not a tech geek you will be able to use this tool easily., All you need to do is just drag and drop the desired actions, save and dominate.
As an example, I will review the implementation of a series of problems.
For example, suppose you have several projects to use the power of the link partners. You can literally set it up right at20 and leave it as it is . Return to the newly harvested URLs and high PR URLs.
We start by preparing our keywords, combining them with the footprints and then storing them in a folder. Project1, Project2, Project3, etc.
Screenshot Credit: http://www.jacobking.com
Simply just harvest the URL, delete duplicates, verify the Page Rank, wait a few seconds and try again.
After adding the commands, filling the details are easy to understand. You will find that I put a wait command right between the individual loops.
Just configure it in 5 seconds for Scrapebox to breathe quickly between the harvesting process and. I have also added the email notification command at the end, which is like the icing on the machine and that’s quite interesting.
9.The Scrapebox Add-Ons (FREE)
Scrapebox generally comes with a complete set of free add-ons. It is a good idea to become familiar with them if you need them. All you need to do is go to the “Add-ons” tab and navigate through the list. All the accessories already installed will be green and the red ones available that you can install as per your requirements.
Backlink Checker:
This plugin needs information from the Moz API. After entering, you can scan up to 1000 backlinks easily once in a go.
Alive Checker:
The add-on allows you to check the status of each site and even track redirects to indicate the final destination.
Google Image Grabber:
You can delete the images from Google based on the keywords you entered. You can download them or preview them on your PC.
Alexa Rank Checker: Check the Alexa ranking of your collected URLs easily effortlessly.
Duperemove: Simply merge several files up to 180 million lines and eliminate the duplicates ones. Work with large files and save the results to your liking.
The Page Scanner: Create custom footprints right in the form of text and HTML code, and then massively analyze the source code of the URL for those footprints. Then, you can export the matches to separate files.
The Rapid Extender: Now you can submit your backlinks to various statistical sites, whois sites and similar sites to force indexing.
Audio player – Increase some melodies while scraping the data.
Port Scanner: It generally shows all active connections and IP addresses and corresponding ports. Useful to debug and monitor connections.
The Articles Scraper: Now you can easily scrape the articles from several article directories and save them in txt format as well.
Dofollow test: Simply load a list of backlinks and see if it is Dofollow or Nofollow. It’s a time saving add-on that you can use before blog commenting.
Bandwidth meter: Show your speed up and down.
Page Authority: Collect the authority of the page, the authority of the domain and the external links for the massive URLs right in the harvester.
The Blog Analyzer: Simply analyze the URLs of the harvesters in order to determine the blog platform (WordPress, Movable), open comments, protection against spam and captcha images.
Google Competition Finder: Just check the number of indexed pages in order to get a specific list of keywords. Enter matching results that are broad or accurate.
The Sitemap Scratcher: Just get URL directly from the XML sites or from the AXD site map. It also has the Deep Crawl function, which shows all the URLs in the site map and those that are not shown in the site map.
Malware and Phishing Filter: Bulk has detected websites that contain or contain malware during the last 90 days.
So these are few of the free add-ons that you’re going to get with this Scrapebox SEO Tool. The Backlink Checker and the Article Scraper is my best add-on and I’m really impressed with these add-on while doing SEO work.
Final Thoughts:
As of now you have got all the detailed insights of this Scrapebox SEO tool. You can now use each and every feature in order to get most benefit out of this tool. And trust me this tool is really going to help you in long run.
Here at BloggDesk we have used and test all the features of this tool and guess what we have got some interesting results. With this Scrapebox Guide you can easily find the better insights of its features like the Keyword Research, Backlinks, The Footprint Finder, The Automater and more in a row.
Actually, it’s a long tutorial so make sure you have time to understand and master all the features properly. However, for the average user, it can be a fairly complex tool that is difficult to navigate, and you probably will not know how to extract the data you’re actually looking for. But with our useful and easy guide you can use this tool easily with any efforts.
We hope you find this Scrapebox Guide useful. Feel free to comment and tell us which is your favourite SEO tool that you use for your blog or website.
And if you do like the post, then make sure you share it on social media channels like Facebook, Twitter and LinkedIn.
Also visit :
Best Proxy Server For Personal Use

